Changes to the data flow in Run 2
Learning Objectives
Understand how the LHCb data flow differs between Run 1 and Run 2
Run 1 of the LHC ran from 2010 to the end of 2012. Run 2 began in the middle of 2015 and finished at the end of 2018. During Run 1 the LHC provided proton-proton collisions at a centre-of-mass energy of 7 and 8 TeV, and in Run 2 the energy was increased to 13 TeV. With an increase in energy comes an increase in production cross-sections, and so a much higher rate of interesting events.
So now we have many more events that we would like to store, but as ever we’re limited by computing resources. To help overcome this, LHCb introduced the Turbo stream in 2015, whereby the selection of candidates made in the second stage of the high level trigger, HLT2, is saved to disk and used directly by analysts, with no further offline reconstruction by Brunel.
Omitting the offline reconstruction is usually a Bad Idea because it’s usually of a much better quality than the reconstruction performed in the HLT (the ‘online reconstruction’) as there’s more time to run it. But, thanks to an enormous effort improving the reconstruction software both online and offline in between Run 1 and Run 2, the two reconstructions now perform identically. This means if HLT2 performs all the reconstruction you need in your analysis, there’s no need to wait for the offline reconstruction to run! This saves a lot of time (it’s Turbo, after all), and hence money.
However you still have many more events to save. To overcome this, events saved to the Turbo stream contain only the candidates that were reconstructed in the trigger. That is to say, any tracks or detector responses that don’t form part of the decay that the trigger line uses to evaluate its selection is thrown away. This is quite pragmatic, because a lot of analyses don’t use this information anyway.
The Turbo stream runs in parallel with the regular data flow, and so everything now looks like this:
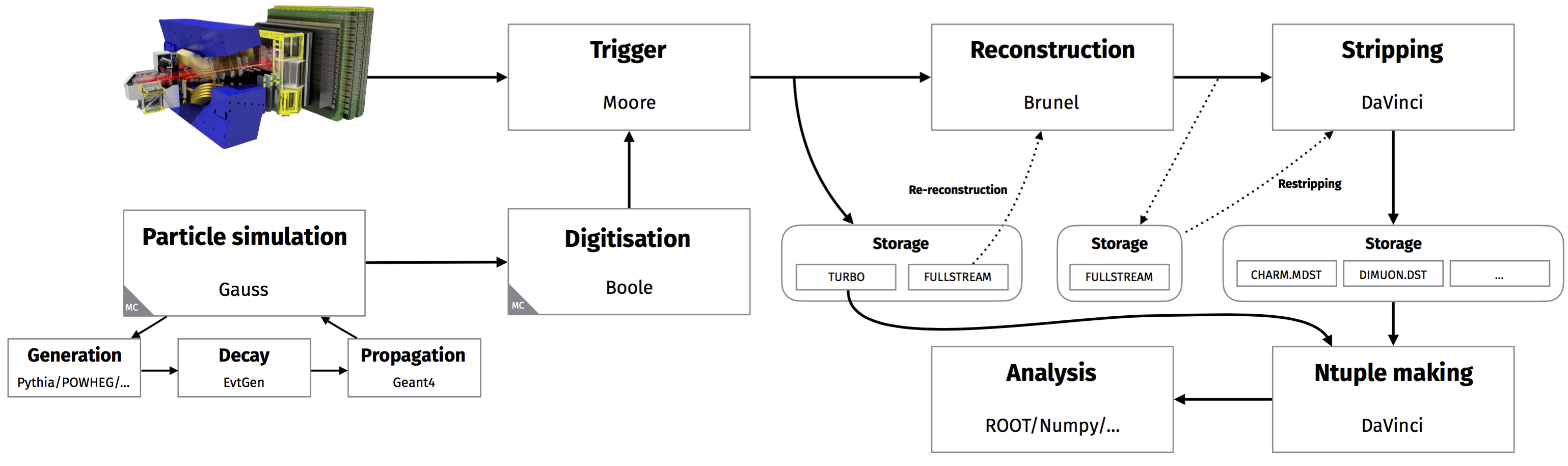
The change here is the addition of the Turbo stream in the storage output of the trigger. This stream cannot be re-reconstructed because the information needed to do that is thrown away to save disk space.
For the topics covered in this course, though, this doesn’t change things much because we can run DaVinci over the Turbo stream in exactly the same manner as for the stripping output. We will just need to look in a different place to find the selection definitions, this time for trigger lines rather than stripping lines.
It’s best to ask the trigger coordinator in your working group if your analysis has a trigger line that outputs to the Turbo stream, and if so where to find the selection definitions.
The different types of Turbo
As the Turbo data flow model has evolved throughout Run 2, the capabilities of Turbo have changed. Each capability has a different name, which can be useful to know.
Turbo: Saving of the candidate that fired the trigger line. The entire decay tree of the object is saved (i.e. including descendants).
Turbo++, or PersistReco: In addition to Turbo, the rest of the reconstruction performed in HLT2 is also saved when the trigger line fires. This includes all long and downstream tracks, all tracks associated to the primary vertex reconstruction (VELO tracks), and all particle identification objects. This allows you to perform arbitrary combinatorics offline.
TurboSP: For ‘Turbo with selective persistence’, in addition to Turbo you can specify additional objects to save. These additional objects are usually the subset of the reconstruction that’s relevant for your physics analysis, such as the set of particles that combine with the trigger candidate and form a good-quality vertex. TurboSP is a compromise between Turbo, where you can only do analysis on what you used in the trigger but use little space, and Turbo++, where you can do many things offline but use a lot of space.
For more details on how the software evolved and currently known issues, please check the Run2OperationSummary and Run2TriggerChangelog TWikis.
TurboSP is considered as the primary data flow model for the planned LHCb upgrade in Run 3.